






Data Pipeline Journey: Exploring Steps to Transform Data
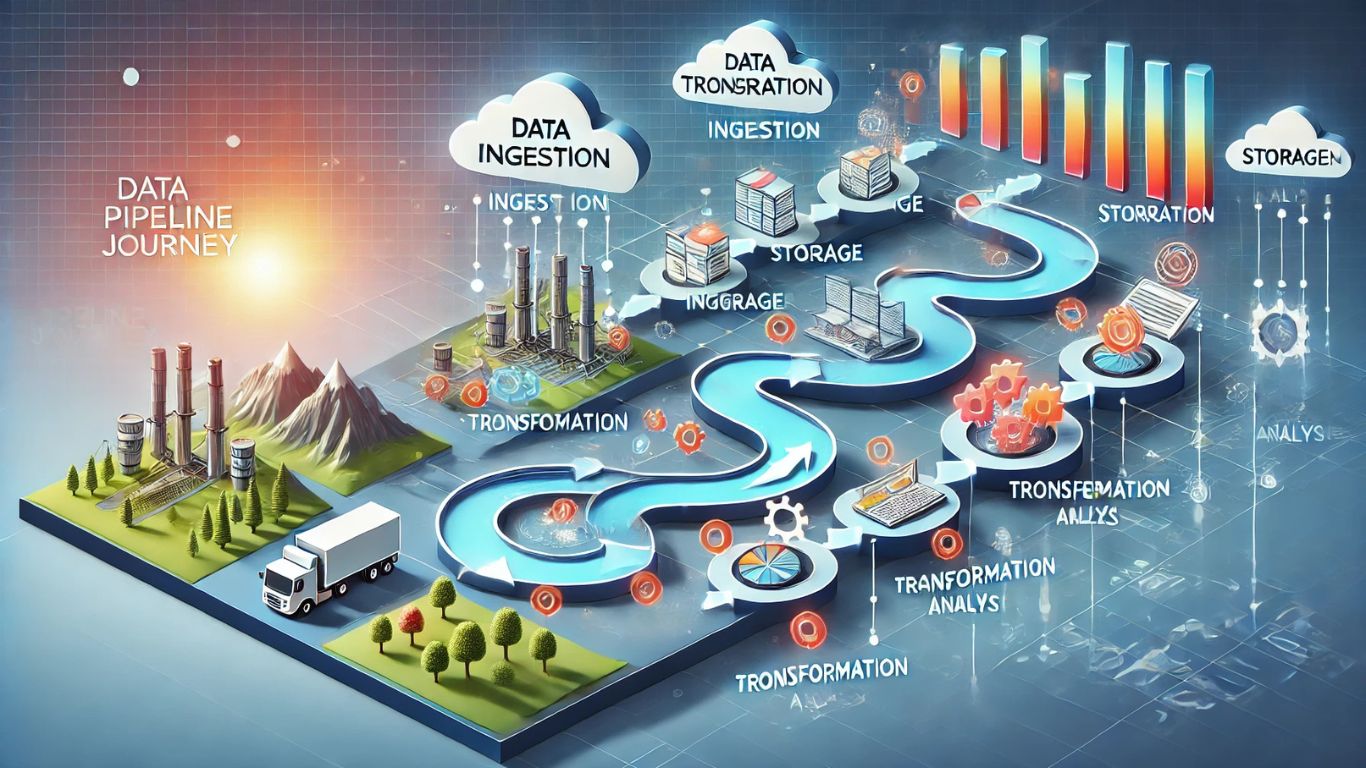
A data pipeline journey is crucial for transforming raw information into actionable insights. This process ensures data flows seamlessly through various stages, offering businesses valuable tools for decision-making. By implementing effective pipeline strategies, organizations gain a robust framework for managing complex data ecosystems.
Understanding the Data Pipeline Journey
At its core, the data pipeline journey refers to the steps taken to move data from source systems to its final destination. This journey begins with data collection and ends with meaningful insights. Each stage of the pipeline contributes to making raw data organized, accessible, and usable. Transitioning through these stages enhances efficiency and reliability.
Why a Data Pipeline Journey Matters
In today’s digital world, data streams continuously from various sources. Without a structured pipeline, this data can become fragmented and unusable. By undertaking a data pipeline journey, businesses ensure consistency and clarity in data usage. Moreover, it prevents data silos and fosters collaboration among departments.
Key Components of a Data Pipeline Journey
Data Collection
The journey starts with data collection from sources like databases, APIs, or IoT devices. This raw data can vary in format, size, and quality. Collecting data efficiently sets the foundation for the pipeline.
Data Ingestion
Once collected, data ingestion moves the information into a central repository. This step involves choosing batch processing or real-time ingestion, depending on the use case.
Data Storage
Data needs to be stored securely before further processing. Cloud-based solutions or on-premise databases are often used for this purpose. Efficient storage ensures scalability and accessibility.
Data Transformation
Raw data undergoes cleaning and formatting during the transformation stage. Here, duplicates are removed, and errors are corrected. Additionally, structured formats are created to meet specific analytical needs.
Data Integration
Data from different sources is combined to provide a unified view. This integration creates a seamless connection between various datasets, enabling holistic analysis.
Data Analysis and Visualization
At the final stage, data is analyzed to extract insights. Visualization tools like dashboards or reports present these findings clearly, aiding decision-making processes.
Challenges Encountered in a Data Pipeline Journey
While building a pipeline, several challenges arise. Data quality issues, compatibility concerns, and scaling difficulties are common hurdles. However, these can be mitigated with robust planning and advanced tools.
Optimizing Your Data Pipeline Journey
Optimization ensures the pipeline runs smoothly with minimal resource use. Employing automation tools and monitoring systems reduces errors and downtime. Regular updates to infrastructure also maintain efficiency.
Best Practices for a Successful Data Pipeline Journey
- Start Small: Begin with manageable datasets to avoid overwhelming complexity.
- Automate Repetitive Tasks: Automation tools save time and increase accuracy.
- Monitor Performance: Regular performance checks ensure the pipeline remains efficient.
- Invest in Scalability: Design pipelines to handle growing data needs.
Real-World Applications of a Data Pipeline Journey
The journey is essential in industries such as healthcare, finance, and e-commerce. For example, in e-commerce, a data pipeline helps analyze customer behavior, improving product recommendations.
Tools Used in a Data Pipeline Journey
Popular tools like Apache Kafka, Google Dataflow, and Talend are often used. These tools simplify tasks like ingestion, transformation, and storage.
Future of the Data Pipeline Journey
As technology evolves, data pipeline strategies are becoming more sophisticated. Artificial intelligence and machine learning are now integrated into pipelines, enabling predictive analytics and automation.
FAQs
What is a data pipeline journey?
A data pipeline journey refers to the process of collecting, transforming, storing, and analyzing data to generate useful insights.Why is a data pipeline journey important?
It ensures data flows smoothly between systems, eliminates silos, and provides businesses with accurate and actionable insights.What are the key stages of a data pipeline journey?
The main stages include data collection, ingestion, storage, transformation, integration, and analysis.What challenges are faced during a data pipeline journey?
Common challenges include data quality issues, system compatibility problems, and scalability concerns.Which tools are used in a data pipeline journey?
Popular tools include Apache Kafka, Google Dataflow, and Talend, which streamline various stages of the pipeline.How can a data pipeline be optimized?
Optimization involves automating tasks, monitoring performance, and ensuring infrastructure scalability to handle growing data demands.


